Sisteme expert
Conform uneia dintre cele mai
răspândite definiţii ale sistemului expert (SE), acesta este
un program de calcul care incorporează cunoştinţele unui expert
uman şi încearcă să simuleze raţionamentele
desfăşurate de acesta din urmă în scopul rezolvării unei
anumite probleme din domeniul său de expertiză. La rândul său, expertul
este un specialist care stăpâneşte foarte bine un anumit domeniu.
Atributele care deosebesc expertul de un începător au în mare parte un
caracter simbolic, se sprijină pe cunoştinţe dobândite în timp
şi decurg din raţionamente care încearcă să pună de
acord aceste cunoştinţe cu faptele specifice problemei studiate.
Până
în prezent, domeniile de interes în care s-au înregistrat cele mai numeroase
implementări ale SE sunt : inginerie şi producţia de
mărfuri (35%) ; afaceri (28%) ; medicină (11%) ; mediu
şi energie (9%); agricultură (5%) ; telecomunicaţii
(4%) ; administraţie (4%) ; legislaţie (3%) şi
transporturi (1%) [Liebowitz 97].
În
domeniul electroenergeticii, principalele aplicaţii ale SE se referă
la : (a) conducerea operativă a sistemului energetic; (b) analiza on
/ off – line a funcţionării sistemului electroenergetic; (c) analiza
şi reconfigurarea postavarie a
reţelelor electrice; (d) mentenanţa
echipamentelor din sistemul electroenergetic; (e) dezvoltarea reţelelor
de distribuţie ş.a.
Cunoştinţe
Elementul
central, în jurul căruia gravitează toate celelalte componente ale
unui SE, îl reprezintă cunoştinţele. De aceea, SE se mai
numesc şi Sisteme Bazate pe Cunoştinţe. În cadrul unui
SE, reprezentarea cunoştinţelor se poate face pe mai multe căi,
cum ar fi regulile de producţie, cadrele şi cazurile.
Dintre aceste forme de reprezentare, cea mai răspândită este cea a
regulilor de producţie.
Cadrele
(în engleză, frames) reprezintă obiecte complexe care sunt
descrise de anumite proprietăţi sau atribute şi anumite proceduri
sau metode. Structural, cadrele sunt foarte asemănătoare cu obiectele
folosite în cadrul programării la nivel obiect. Astfel, una din
proprietăţile cele mai importante ale cadrelor este mecanismul de
moştenire, care permite descrierea generică a unui obiect şi
crearea de instanţe ale acestuia care moştenesc toate atributele
obiectului generic, la care se adaugă şi atribute noi.
Reprezentarea
cunoştinţelor sub formă de cazuri are la bază
premisa că, pentru a învăţa şi a rezolva probleme complexe,
oamenii folosesc raţionamentul analogic sau cel experimental. Cazurile
folosite pentru desfăşurarea analogiilor constau în informaţii
despre situaţia analizată, soluţia problemei în sine,
rezultatele care se obţin prin adoptarea acelei soluţii, anumite
atribute care pot evidenţia tipare specifice.
Cunoştinţele
folosite de un SE pot fi împărţite în cunoştinţe faptice
şi cunoştinţe euristice. Cunoştinţele faptice
reprezintă acea parte a cunoştinţelor despre domeniul de
interes, care sunt cunoscute şi se găsesc în manuale sau reviste. De
cealaltă parte, cunoştinţele euristice reprezintă
cunoştinţe mai puţin riguroase, deduse prin experimente
şi/sau raţionamente specifice. Aceste cunoştinţe sunt mai
puţin formalizate şi reflectă mai degrabă buna
practică din domeniul respectiv.
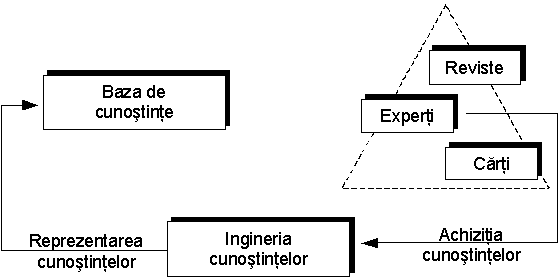
Dezvoltarea
unui SE presupune în primul rând culegerea cunoştinţelor relevante de
la experţii umani sau de la alte surse. Achiziţia
cunoştinţelor în vederea reprezentării lor în programe de calcul
nu este în general o sarcină simplă. Ca urmare, s-a dezvoltat o
adevărată disciplină a construirii SE, denumită ingineria
cunoştinţelor, al cărui principal obiectiv este transferul
cunoştinţelor de la sursele uzuale (experţi, cărţi,
reviste etc) către baza de cunoştinţe a SE.
Reguli de
producţie
Reprezentarea
cunoştinţelor asigură formalizarea şi organizarea acestora.
Cea mai des utilizată schemă de reprezentare a
cunoştinţelor este regula de producţie, denumită
uneori regula IF –
THEN. Regulile de
producţie descriu cunoştinţele
faptice şi cele
euristice pe care le folosesc în mod curent experţii umani. Ansamblul
acestor reguli formează baza de reguli a SE, denumită uneori
şi bază de cunoştinţe.
O
regulă de producţie constă dintr-o condiţie sau premisă,
urmată de o acţiune sau concluzie şi are forma IF
<condiţie> THEN <acţiune>. În general, partea
de acţiune a unei reguli poate conţine : (i)
acţiuni cu efect descriptiv, de exemplu afişarea unui mesaj pe
ecranul monitorului ; (ii) verificarea unei alte reguli, în cazul
sistemelor de reguli înlănţuite şi (iii) adăugarea
unui nou fapt în baza de fapte a SE.
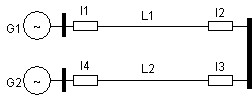
De
exemplu, pentru schema monofilară din Fig. 13.21, localizarea defectelor
pe una din cele două linii sau identificarea unei funcţionări
defectuoase a sistemului de protecţii pot fi realizate folosind
următorul set de reguli:
Regula
1: IF (Deconectează I1 şi I2) THEN
(Defectul este pe linia L1)
Regula 2:
IF (Deconectează I3 şi I4) THEN (Defectul este pe linia
L2)
Regula 3:
IF (Deconectează I1 şi I4) OR
(Deconectează I2
şi I3)
THEN
(Protecţia nu a funcţionat corect)
SE
ce folosesc reguli de producţie implementează două tipuri de
strategii :
·
Strategii bazate pe date,
care utilizează tehnici deductive pentru a stabili noi concluzii,
pornind de la un set de date existente.
·
Strategii bazate pe scopuri,
care utilizează tehnici inductive pentru a verifica o anumită
ipoteză.
De
exemplu, pentru regulile de mai sus şi schema monofilară alaturata,
se poate aplica o strategie bazată pe date care, pornind de la starea
întrerupătoarelor din reţea (de exemplu I1 şi I2 deschise,
respectiv I3 şi I4 închise), localizează defectul care a condus la
starea respectivă (în cazul de faţă, defectul s-a produs pe
linia L1).
Aplicarea
strategiei bazate pe scopuri este ilustrată cu ajutorul unui exemplu care
realizează analiza nivelului tensiunii pe barele consumatorului din Fig. De
mai jos, în trei ipoteze privind mijloacele de reglare a tensiunii, şi
anume : (i) compensarea puterii reactive; (ii) modificarea
raportului de transformare şi (iii) modificarea numărului de
transformatoare în paralel.

Pentru acest sistem se consideră
următoarele reguli :
Regula
1: IF (QK
scade) OR
(KT
scade) OR
(NT =2 ®
NT=1) THEN (U2 scade)
Regula 2:
IF NOT(Regim de
sarcină maximă) THEN (NT=2 ®
NT=1)
Regula 3:
IF (QK=QKmin)
THEN (KT scade)
Regula 4:
IF (QK creşte) OR
(KT
creşte) OR
(NT=1 ®
NT=2) THEN (U2 creşte)
Regula 5:
IF (Regim de sarcină
maximă) THEN (NT=1 ® NT=2)
Regula
6: IF (QK=QKmax)
THEN (KT creşte)
Structura SE
Cea mai comună structură a SE este cea
descrisă în Fig. urmatoare Comunicarea între sistem şi utilizator sau
expertul uman se realizează prin intermediul unei interfeţe
special concepute. Celelalte componente importante ale unui SE sunt baza de
cunoştinţe, motorul de inferenţă, sistemul de
explicare şi editorul bazei de cunoştinţe. În
continuare vor fi descrise succint fiecare dintre aceste componente.
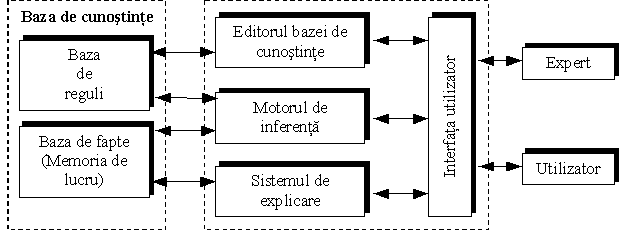
Interfaţa
utilizator. Comunicarea între operator şi SE se
realizează prin intermediul unei interfeţe specializate, care
poate folosi meniurile cu care
suntem familiarizaţi din aplicaţiile Windows, dialogul
într-un limbaj natural sau orice altă
formă
de interacţiune. Pentru simplificarea comunicării este de dorit ca
interfaţa utilizator să fie cât mai prietenoasă şi
inteligentă, adică să ştie cum să prezinte
informaţiile şi să cunoască preferinţele utilizatorului.
Baza
de cunoştinţe. La nivelul unui SE, baza de
cunoştinţe are doua componente : baza de reguli
şi baza de fapte. Baza de reguli conţine cea mai mare parte a
cunoştinţelor necesare rezolvării problemelor. SE complexe
folosesc baze de reguli cu un număr mare de reguli, de la câteva sute,
până la câteva mii. Baza de reguli reprezintă memoria pe termen
lung a sistemului, deoarece conţine partea hard a
cunoştinţelor folosite de SE.
De
partea cealaltă se află memoria pe termen scurt sau memoria
de lucru, formată din baza de fapte, ce descrie contextul
problemei şi conţine datele de intrare, cele de ieşire şi
orice date intermediare produse ca urmare a desfăşurării
inferenţelor de către motorul de inferenţă.
Reprezentarea
şi organizarea bazei de cunoştinţe sunt două aspecte
esenţiale pentru funcţionarea corectă a SE. Dacă se
doreşte ca după formarea SE acesta să se poată dezvolta
este absolut necesar ca baza de cunoştinţe să fie complet
separată de restul sistemului.
Motorul
de inferenţă. Mecanismul specific care permite
simularea raţionamentelor desfăşurate de expertul uman este inferenţa.
Conform definiţiei de dicţionar (DEX), inferenţa este
operaţia logică de trecere de la un enunţ la altul şi în
care ultimul enunţ este dedus din cel anterior.
Motorul
de inferenţă controlează modul şi
succesiunea în care se aplică cunoştinţele din baza de reguli
asupra datelor din baza de fapte. De fapt, motorul de inferenţă este
un program de calcul care aplică regulile asupra faptelor, pentru a genera
prin inducţie, fie fapte noi care se adaugă în baza de fapte, fie
confirmarea sau infirmarea unei ipoteze, fie soluţia propriu-zisă a
problemei.
În
principiu, motorul de inferenţă conţine un interpretor,
care analizează şi procesează regulile din baza de reguli
şi un planificator, care stabileşte ordinea în care se
aplică regulile. Motorul de inferenţă parcurge baza de reguli,
căutând identificarea unei corespondenţe între faptele din
condiţiile sau consecinţele regulilor şi informaţiile
existente în baza de fapte. În momentul în care se identifică o asemenea
corespondenţă, regula respectivă este folosită pentru a
produce un nou fapt sau pentru a confirma o ipoteză.
La
nivelul planificatorului, selectarea regulii care se aplică la un
moment dat foloseşte una din următoarele strategii :
·
Selectarea regulii celei mai specializate.
Dintre două reguli –X şi
Y – se selectează cea
care conţine numărul maxim de condiţii, considerată ca
fiind specializată, în raport cu cealaltă, care are un caracter
general.
- Selectarea regulii celei mai productive.
Dintre două reguli –X şi Y – se selectează cea care
conţine numărul maxim de consecinţe, adoptând ipoteza
că “mai mult înseamnă mai bine „.
- Selectarea euristică.
Dintre mai multe reguli care pot fi aplicate la un moment dat, se alege
cea care conduce baza de fapte cât mai aproape de starea dorită.
·
Selectarea pe baza încrederii.
Unora dintre reguli li se acordă o încredere sporită, iar la
selectarea regulii care se aplică la un moment dat se ţine seama cu
prioritate de încrederea acordată regulilor.
Editorul
bazei de cunoştinţe. Unele
SE sunt dotate cu un editor pentru baza de cunoştinţe, care
ajută utilizatorul, expertul sau inginerul de cunoştinţe să
actualizeze şi să verifice conţinutul bazei de
cunoştinţe şi, în special, conţinutul bazei de reguli.
Existenţa editorului asigură totodată o dezvoltare comodă a
sistemului, după implementarea sa.
Funcţionarea SE
Forţa unui SE este capacitatea
acestuia de a desfăşura inferenţe şi de a trage concluzii
pe baza unor premise. De fapt, această capacitate conferă inteligenţă
SE. Sarcina motorului de inferenţă este de a deduce unele concluzii
sau verifica unele ipoteze prin punerea de acord a datelor din baza de fapte cu
regulile din baza de reguli, aşa cum este ilustrat în Fig. 1. Îndeplinirea
acestei sarcini este posibilă prin aplicarea a două tipuri de
strategii: înlănţuirea înainte şi
înlănţuirea înapoi.
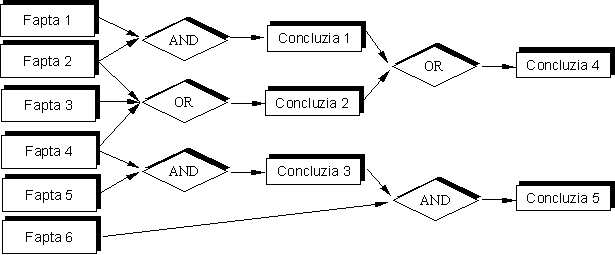
Fig. 1 – Principiul de desfăşurare a
inferenţelor în cadrul unui SE bazat pe reguli.
În cazul înlănţuirii înainte, motorul de
inferenţă examinează starea curentă a bazei de
cunoştinţe, urmărind identificarea regulilor ale căror
premise sunt satisfăcute de datele din baza de fapte. Aceste reguli sunt
aplicate şi faptele care rezultă ca şi concluzii ale lor sunt
adăugate în baza de fapte. În continuare, baza de cunoştinţe
este reexaminată şi se repetă procesul descris mai sus,
până la stabilirea unei concluzii finale, care poate reprezenta sau
nu o soluţie a problemei. Acest proces este ilustrat în Fig. 2.
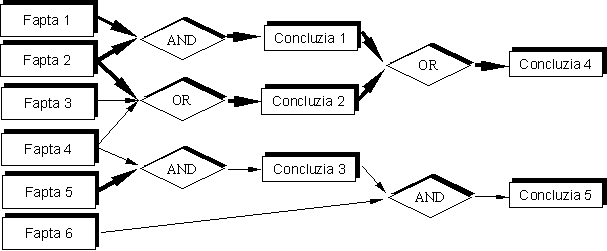
Fig. 2 – Funcţionarea
motorului de inferenţă după strategia înlănţuirii
înainte (cu linie îngroşată sunt reprezentate faptele adevărate,
iar cu linie simplă, cele false).
Înlănţuirea
înapoi este o strategie bazată pe scopuri
în sensul în care se încearcă confirmarea concluziei unei reguli
(privită ca un scop), demonstrând validitatea tuturor premiselor acestei
reguli. Aceste premise, pot fi la rândul lor concluziile altor reguli (caz în
care motorul de inferenţă va intra într-un proces recursiv, încercând
să demonstreze validitatea premiselor acelor reguli) sau pot reprezenta fapte
independente, furnizate ca date de intrare în baza de fapte.
Desfăşurarea unui asemenea proces de căutare este ilustrată
în Fig. 3.
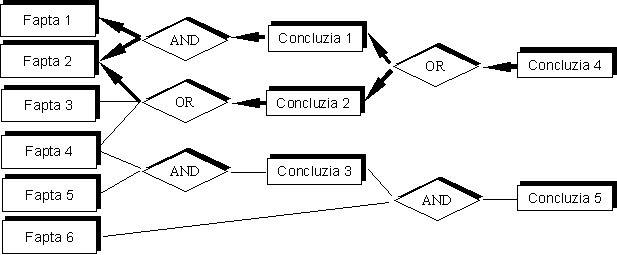
Fig.
3 – Funcţionarea motorului de inferenţă
după strategia înlănţuirii înapoi. Verificarea ipotezei asociate
concluziei 4.
Desfăşurarea inferenţelor prin aplicarea
înlănţuirii înainte sau înapoi este echivalentă cu parcurgerea
într-un sens sau altul a grafului de decizie din Fig. 2 şi 3, putându-se
aplica una din strategiile de căutare cunoscute. Pe de altă parte, se
menţionează că, în raport cu tipurile de strategii definite
anterior, strategiile bazate pe date folosesc înlănţuirea
înainte, iar strategiile bazate pe scopuri folosesc înlănţuirea
înapoi.
Funcţionarea
SE se poate desfăşura în trei moduri : (i) modul de
achiziţie a cunoştinţelor ; (ii) modul de
consultare şi (iii) modul de explicare.
SE
se găseşte în modul de consultare atunci când se află în
dialog cu utilizatorul în vederea stabilirii
unei soluţii pentru
o problemă dată.
Utilizatorul transmite SE date care descriu problema respectivă,
iar sistemul răspunde folosind motorul de inferenţă pentru
modelarea / simularea raţionamentelor necesare deducerii
răspunsurilor la întrebările utilizatorului. Modul de consultare
presupune utilizarea pe scară largă a motorului de
inferenţă, putându-se aplica oricare din cele două mecanisme de
inferenţă – înlănţuirea înainte sau înapoi.
Unul
din atributele cele mai puternice ale SE este capacitatea lor de a explica
inferenţele pe care le realizează. Această capacitate are la
bază arborii AND / OR care sunt construiţi pe măsura
desfăşurării inferenţelor. Modul de explicare pune
la dispoziţia utilizatorului cunoştinţele SE într-un mod
explicit. Pe această cale, sistemul explică cum a ajuns la o
anumită concluzie, de ce a realizat o anumită acţiune sau
oferă răspunsuri la o întrebare de forma „ce-ar fi dacă ?”.
De exemplu, în Fig. 4 şi Fig. 5 se indică schemele de principiu
după care sistemul răspunde la întrebările cum şi de
ce.
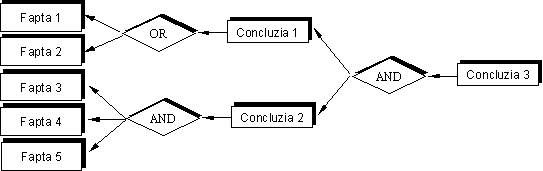
Fig.
4 – Explicarea modului cum s-a ajuns la o anumită
concluzie.
Astfel, pentru a se explica cum s-a ajuns la o
anumită concluzie, se parcurge arborele de decizie AND/OR în sens invers.
De exemplu (Fig. 4), Concluzia 3 a fost stabilită ca urmare a
existenţei Concluziei 1 şi Concluziei 2. La
rândul ei, Concluzia 1 a fost stabilită deoarece una din Faptele
1 sau 2 sunt adevărate.
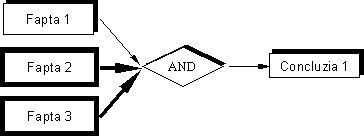
Fig. 5 – Explicarea faptului de ce se realizează o
anumită acţiune.
În cazul schemei din Fig. 5, pentru a
răspunde de ce se realizează o anumită acţiune,
sistemul trebuie să identifice mai întâi obiectivul curent şi să
justifice acest obiectiv prin verificarea condiţiilor care conduc la
atingerea lui. Astfel, în ipoteza în care Faptele 2 şi 3
sunt verificate, sistemul poate interoga utilizatorul asupra
validităţii Faptei 1, în scopul stabilirii
validităţii Concluziei 1.
Mulţimi
fuzzy
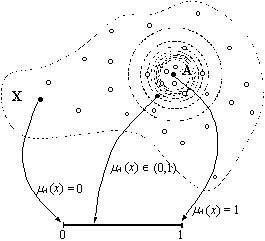
O
mulţime fuzzy este o mulţime a cărei graniţă nu este
evidentă, bine definită. În general, o mulţime fuzzy
conţine elemente despre care se poate spune că aparţin (sau nu
aparţin) parţial acelei mulţimi. O mulţime fuzzy A,
definită pe o mulţime X, este formată din perechi ordonate
(x ; mA(x)),
unde x este un element din mulţimea X, iar mA(x)
este un element care poate lua valori în intervalul [0,1] şi descrie
măsura în care elementul x aparţine sau nu mulţimii A.
Astfel, se poate scrie:
![]()
mA(x)
este funcţia caracteristică sau funcţia de
apartenenţă asociată mulţimii fuzzy A, iar
valoarea acestei funcţii se numeşte grad de apartenenţă.
O singură pereche de forma (x ; mA(x)) se numeşte singleton
fuzzy, astfel încât întreaga mulţime fuzzy A poate fi tratată
ca reuniunea tuturor singleton-urilor fuzzy din care este formată.
De exemplu, în cazul unui univers de discurs finit, enumerabil, mulţimea
fuzzy A poate fi reprezentată ca un vector de singleton-uri:
![]()
Mulţimea
în care variabila x poate lua valori, notată X, se
numeşte univers de discurs.
Pentru aplicaţiile care se adaptează cel mai bine abordării
fuzzy universul de discurs nu poate fi definit simplu folosind valori numerice.
Asemenea situaţii pot interveni, de exemplu, atunci când ne referim la
gust sau la impactul estetic al unor obiective. În asemenea situaţii se
folosesc valorile sau categoriile lingvistice, cum ar fi (acru, dulce, amar,
sărat,…) în cazul gustului sau (urât, neplăcut, indiferent,
atrăgător, frumos …) în cazul impactului estetic.
Dacă
în cazul unei variabile algebrice se
folosesc ca valori numerele (de exemplu, tensiunea într-un nod al reţelei
poate avea valori ca 105,7 kV sau 117,2 kV), în cazul variabilelor lingvistice, valorile folosite sunt cuvinte, expresii sau chiar propoziţii.
De exemplu, variabila lingvistică „gust” poate lua valori cum ar fi acru
sau dulce, în timp ce variabila lingvistică „impact estetic” poate
lua valori cum ar fi neplăcut sau frumos.
Abordarea
lingvistică reprezintă de fapt una din caracteristicile fundamentale
ale mulţimilor fuzzy. De aceea, chiar şi atunci când universul de
discurs poate fi descris pe cale numerică, se preferă asocierea la
această descriere şi a unor categorii lingvistice. În acest caz,
valorile lingvistice folosite joacă rolul variabilelor sau constantelor domeniu
folosite în limbajele de programare uzuale, respectând şi o anumită
ordine. De exemplu, pentru valoarea tensiunii într-un nod al reţelei se pot
folosi valori lingvistice cum ar fi (foarte-mică, mică, medie, mare,
foarte - mare). Fiecăreia din aceste valori lingvistice, tratată ca o
mulţime fuzzy, îi este asociat un anumit domeniu numeric de variaţie
a tensiunii.
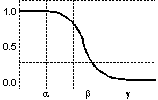
Apartenenţa
la o mulţime fuzzy
Mulţimile
fuzzy descriu întotdeauna proiecţia universului discursului sau a unei
părţi a acestuia pe intervalul
[0,1] , denumit şi spaţiu de apartenenţă. Această proiecţie se
realizează prin intermediul funcţiei de apartenenţă mA : X
® [0,1], a
cărei valoare mA(x)
descrie gradul de apartenenţă al valorii x
la mulţimea fuzzy A. O valoare mA(x) º 1
reprezintă apartenenţa completă a elementului x la
mulţime A; valoarea mA(x) º 0
reprezintă non-apartenenţa completă a lui x la A;
în sfârşit, o valoare intermediară a funcţiei caracteristice, mA(x)
Î (0,1),
descrie un grad de apartenenţă intermediar. Acestei definiţii i
se poate asocia reprezentarea grafică mai jos.
În
general, pentru un anumit tip de problemă, nu se defineşte o
singură mulţime fuzzy A, ci mai multe asemenea mulţimi Ai
, care se întrepătrund: altfel spus, funcţiile de
apartenenţă mA(x)
sunt definite pe submulţimi ale universului X care au elemente comune.
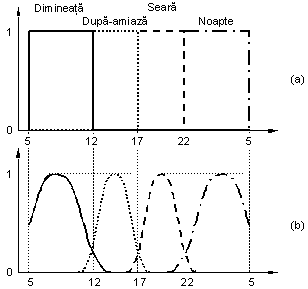
Exemplul care urmează ilustrează tocmai acest aspect. Este cunoscut
faptul că, din punctul de vedere al programului de lucru, începutul
fiecărei perioade din zi este foarte bine precizat. Acest fapt conduce la
funcţii de apartenenţă discontinui (Fig. a ), care descriu de
fapt un model boolean (numai dimineaţă, numai
după-amiază, numai seară sau numai noapte). Pe de
altă parte, din punctul de vedere al condiţiilor meteorologice, cum
ar fi nebulozitatea sau gradul de insolaţie, trecerea de la o perioadă
a zilei la alta nu se face brusc ci există intervale de timp în care se
regăsesc condiţii specifice ambelor perioade între care are loc
tranziţia. Pentru a descrie o asemenea evoluţie se pot folosi
mulţimi fuzzy cum sunt cele din Fig. b. Astfel, ora 12 este în
acelaşi timp o oră a dimineţii şi o oră a
după-amiezei, la fel cum ora 22 este simultan oră de seară
şi oră de noapte. În plus, caracterul continuu al funcţiilor de
apartenenţă în cazul reprezentării fuzzy asigură şi o
variaţie continuă a gradului de apartenenţă. De exemplu, nu
tot intervalul 17 – 5 asigură tranziţia între seară şi
noapte; de fapt, această tranziţie are loc în ultimele ore ale serii
şi primele ore ale nopţii.
Un aspect
care reflectă forţa abordării fuzzy o reprezintă libertatea
lăsată utilizatorului în construirea mulţimilor fuzzy şi a
funcţiilor de apartenenţă. Astfel, nicăieri în literatura
de specialitate cititorul nu va întâlni
o reţetă formală pentru calculul gradului de apartenenţă şi aceasta
deoarece chiar dacă gradul de apartenenţă are la un moment dat o
valoare bine determinată, el rămâne o măsură
subiectivă care reflectă modul subiectiv în care interacţionează
utilizatorul cu contextul problemei. Cel mai relevant exemplu în acest sens
este cel al aprecierii etăţii unei persoane. Astfel, o persoană
de 45 ani va fi considerată tânără
de către altcineva care are 90 ani, în timp ce aceiaşi persoană
va fi considerată în vârstă
de un tânăr de numai 15 ani.
]
Funcţii de apartenenţă
Funcţiile
de apartenenţă reprezintă mijlocul prin care se realizează
legătura dintre universul discursului şi măsura
posibilităţii. Alegerea
funcţiei de apartenenţă este o chestiune dependentă de
problemă, singura condiţie pe care trebuie să o
îndeplinească fiind cea de a lua valori în intervalul [0,1]. În rest,
această operaţie se desfăşoară de cele mai multe ori
pe baze euristice şi / sau empirice şi este influenţată în
bună măsură de subiectivismul celui care face alegerea. O serie
de măsuri ale oportunităţi alegerii unei anumite funcţii de
apartenenţă pot fi gradul de adaptare la problemă,
simplitatea modelului de calcul
rezultant, viteza de calcul şi eficienţa.
Principalele
criterii după care se poate realiza clasificarea funcţiilor de
apartenenţă sunt următoarele:
·
clasificarea după modul de reprezentare în calculator;
funcţii continue şi discrete. În forma continuă,
funcţia de apartenenţă este o funcţie matematică cu o
expresie analitică clară sau o funcţie complexă
descrisă de o procedură. În forma discretă, funcţia de
apartenenţă este definită prin puncte, fie folosind un tabel de
definiţie, fie o funcţie originară, continuă.
- clasificarea după natura funcţiilor
folosite pentru generarea lor: funcţii de apartenenţă
generate de funcţii liniare pe porţiuni, funcţii gaussiene, funcţii
sigmoidale şi funcţii polinomiale. Aceste
funcţii sunt, în general, funcţii continue, dar unele dintre ele
pot fi generate şi ca funcţii discrete.
·
clasificarea după formă: funcţii triunghiulare, funcţii trapezoidale, funcţii
gaussiene simple sau complexe, funcţii sigmoidale, funcţii în
formă de clopot etc. Funcţiile triunghiulare şi cele
trapezoidale sunt generate pe baza funcţiilor liniare pe porţiuni;
funcţiile sigmoidale şi în formă de clopot sunt generate fie pe
baza funcţiilor sigmoidale, fie pe baza funcţiilor polinomiale
(pătratice sau cubice).
Câteva
dintre funcţiile de apartenenţă menţionate sunt prezentate mai
jos.
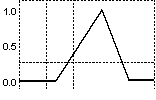

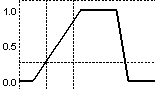
(a) (b) (c)

(d) (e) (f)

(g) (h) (i)

(j) (k)
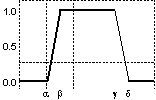
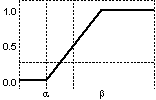
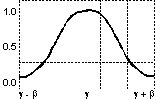
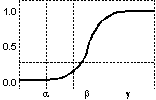
Tipuri de funcţii de
apartenenţă: (a) triunghiulară asimetrică; (b)
triunghiulară simetrică; (c) trapezoidală asimetrică; (d)
trapezoidală simetrică; (e) funcţia rampă-stânga; (f) funcţia
rampă-dreapta; (g) gaussiană; (h) gaussiană complexă; (i)
sigmoidală-S; (j) sigmoidală-Z; (k) în formă de clopot.
Operaţii
fundamentale cu mulţimi fuzzy
După
cum s-a amintit deja, operaţiile cu mulţimi fuzzy care intervin mai
des în diferite aplicaţii practice sunt negarea, reuniunea
şi intersecţia. Pentru aceste operaţii, extinderea
definiţiilor folosite în teoria clasică a mulţimilor este
îngreunată în oarecare măsură de caracterul continuu al
funcţiilor de apartenenţă. Pentru depăşirea acestui
impediment Zadeh propune folosirea complementului faţă de unu
pentru negare, operatorul max pentru
reuniune şi operatorul min
pentru intersecţie.
Cea mai
simplă dintre cele 3 operaţii este negarea. Astfel, pentru o
mulţime fuzzy A caracterizată de funcţia de
apartenenţă mA(x),
mulţimea fuzzy complementară, notată ![]() , va avea funcţia de apartenenţă:
, va avea funcţia de apartenenţă:
![]()
![]()
Reprezentarea grafică
asociată operaţiei de negare este cea din Fig. a.


(a)
(b)
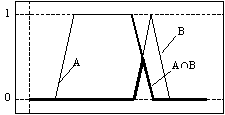
(c)
Reuniunea a
două mulţimi fuzzy A şi B, caracterizate de
funcţiile de apartenenţă mA(x) şi mB(x) produce o
nouă mulţime fuzzy C = A È B, a cărei funcţie de
apartenenţă se determină pe baza operatorului max,
conform relaţiei:
![]()
unde ۷
reprezintă o notaţie alternativă pentru operatorul max.
Reprezentarea grafică asociată reuniunii a două mulţimi
fuzzy este cea din Fig. b.
Intersecţia mulţimilor fuzzy A şi B
produce mulţimea C = A Ç B, a cărei funcţie de
apartenenţă se determină pe baza operatorului min,
şi anume:
![]()
unde ۸ reprezintă o notaţie alternativă pentru
operatorul min. În Fig. c se prezintă imaginea grafică
asociată intersecţiei a două mulţimi fuzzy.
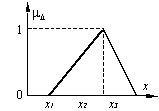
Numere
fuzzy
Dacă mulţimile
fuzzy se deosebesc de mulţimile clasice prin introducerea unui
continuum de valori între extremele adevărat (sau 1) şi fals
(sau 0), atunci numerele fuzzy ar trebui să se deosebească de
numerele tradiţionale printr-o reprezentare care să folosească
un continuum de valori ca aproximări posibile ale numărului exact.
Astfel, în
teoria clasică a mulţimilor nota 8 obţinută la un examen va
fi clasificată ca aparţinând mulţimii notelor medii. De
partea cealaltă, în teoria mulţimilor fuzzy, modelul standard de
reprezentare va considera notă 8 ca aparţinând în proporţie de
0.80 mulţimii notelor medii şi în proporţie de 0.2 mulţimii
notelor mari.
Într-un
spirit asemănător, putem vorbi de numerele 14.92 sau 15.21 ca fiind
aproximări ale numărului exact 15. Mai mult decât atât, valoarea
exactă 15 ar putea fi reprezentată printr-un aşa-numit interval
de încredere, de exemplu [14.7 ; 15.3], considerându-se că orice
valoare din acest interval reprezintă o aproximare „la fel de
exactă” a numărului exact 15.
Următorul
pas pentru trecerea către numerele fuzzy constă în
introducerea caracterului vag al reprezentării acelui număr. Astfel,
cu cât o valoare este mai apropiată de numărul exact 15, cu atât
putem considera că valoarea respectivă reprezintă mai bine acel
număr. Dimpotrivă, cu cât o valoare este mai îndepărtată de
numărul exact, cu atât putem considera că valoarea respectivă
reprezintă mai puţin bine acel număr. Aceste consideraţii
ne duc imediat cu gândul la o reprezentare a numărului fuzzy 15 ca cea din
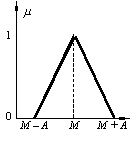
Fig. a.
În
general, un număr fuzzy este un număr real definit pe un interval de
încredere [a, b] şi descris de o funcţie de apartenenţă
care ia valori în intervalul [0,1].
Reprezentarea din Fig. a
sugerează că numărul fuzzy este de fapt o mulţime fuzzy definită pe R.
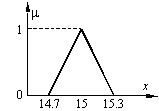
(a) (b) (c)
Logică fuzzy
Logica
fuzzy reprezintă o generalizare a logicii binare, care extinde conceptul
de valoare de adevăr la cel de valoare parţială de
adevăr. Deoarece se bazează pe informaţii imprecise, ambigue
sau vagi, noul tip de logică este de fapt o logică aproximativă,
care are însă marele merit de a reproduce destul de fidel modul în care
oamenii iau decizii : pe baza unor informaţii aproximative şi
imprecise se pot stabili soluţii precise.
Logica
fuzzy este utilizată frecvent în aplicaţii specifice reglajului
automat, unde modelele matematice tradiţionale, deseori extrem de
laborioase, pot fi înlocuite de un set de reguli fuzzy care descriu trecerea de
la starea descrisă de mărimile de intrare, la starea în care se
ajunge ca urmare a comenzii descrise de mărimile de ieşire. Asemenea
sisteme sunt numite sisteme fuzzy.
Dezvoltarea
oricărei aplicaţii care foloseşte logica fuzzy necesită
parcurgerea a trei etape principale, şi anume:
·
Fuzzificarea, în cursul căreia
mărimilor de intrare li se asociază funcţii de
apartenenţă selectate conform anumitor criterii şi, pe baza
acestora, se definesc valorile lingvistice corespunzătoare mărimilor
de intrare şi se trece de la reprezentarea crisp la cea fuzzy.
- Aplicarea setului de reguli fuzzy în
vederea stabilirii gradului de adevăr pentru fiecare din regulile
construite în prealabil, fie pe baza cunoştinţelor unor
experţi umani, fie pe baza unor tehnici speciale de extragere a
acestor reguli.
·
Defuzzificarea, care foloseşte gradele de
adevăr stabilite în etapa anterioară pentru fiecare regulă
şi le aplică consecinţelor acestora pentru a reveni din domeniul
specific mărimilor fuzzy în universul de discurs asociat variabilei sau
variabilelor de ieşire.
În paragrafele
următoare sunt descrise principalele particularităţi ale
fiecăreia din cele trei etape menţionate.
Fuzzificarea
În
majoritatea aplicaţiilor practice
ale sistemelor fuzzy mărimile de intrare sunt descrise de valori crisp
(caracterizate eventual de anumite imprecizii), definite pe un anumit univers
al discursului. De
cealaltă parte, mărimile de ieşire ce
se doresc a fi obţinute descriu mărimi proporţionale cu
gradele de adevăr fuzzy asociate regulilor ce se aplică. În acest
context, prin fuzzificare se înţelege acel proces în cursul
căruia se stabilesc categoriile lingvistice ce descriu universul
discursului, funcţiile de apartenenţă asociate acestor
mărimi şi gradele de apartenenţă ale mărimilor de
intrare la categoriile lingvistice corespunzătoare.
(a) (b) (c)
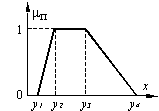
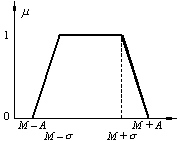
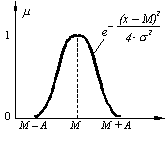
Funcţie
triunghiulară (a), trapezoidală (b) sau gaussiană (c).
O
componentă importantă şi sensibilă a etapei de fuzzificare
o reprezintă construirea funcţiilor de apartenenţă.
Această problemă poate fi abordată pe cale
tradiţională sau folosind elemente ale inteligenţei artificiale,
cum ar fi clasificatorii şi aproximanţii neuronali sau calculul
evolutiv. Construirea funcţiilor de apartenenţă pe căi tradiţionale
foloseşte cunoştinţele experţilor umani şi
raţionamente de forma următoare:

Următorul
exemplu ilustrează modul în care se desfăşoară procesul de
fuzzificare. Se consideră cazul evaluării în paralel a
cunoştinţelor unei persoane folosind două sisteme de evaluare:
note între 1 şi 10, respectiv
calificative (insuficient, suficient, bine, foarte bine). O posibilitate
de modelare a acestor două alternative este cea din figura de mai sus.
Pentru acest exemplu, se folosesc patru mulţimi fuzzy asociate celor patru
categorii lingvistice, pentru care funcţiile de apartenenţă au
următoarele expresii:
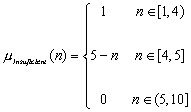

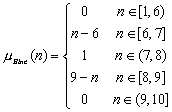
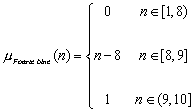
Dacă
nota obţinută nu este mai mare ca 4, calificativul va fi Insuficient,
pentru care funcţia de apartenenţă ia valoarea 1, în timp ce
pentru celelalte valori lingvistice gradele de apartenenţă sunt nule.
Dacă persoana obţine o notă între 4 şi 5, evaluatorul va
avea de ales între calificativele Insuficient şi Suficient.
Decizia evaluatorului va fi luată pe baza unei reguli (oricare ar fi
aceasta) si a unor grade de apartenenţă:
![]()
Pentru acest caz este foarte
probabil că, pe baza regulilor stabilite de experţi, evaluatorul va
acorda calificativul Suficient.
Compunerea
regulilor
Sistemele
fuzzy complexe nu folosesc o singură regulă, ci un set de mai multe
reguli, cum ar fi:

Compunerea
regulilor ce formează sistemul fuzzy se realizează cu ajutorul conectivelor.
Conectivul cel mai des folosit este conectivul SI sau DE ASEMENEA.
Sensul acestui conectiv nu este însă unic, ci se defineşte pentru
fiecare aplicaţie în parte. Trebuie spus însă că de cele mai
multe ori conectarea regulilor se face prin aplicarea operaţiilor de
reuniune (conectarea prin maxim), intersecţie (conectarea prin
minim) sau produs algebric (conectarea prin produs).
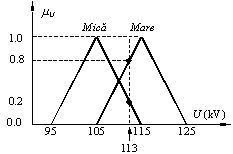
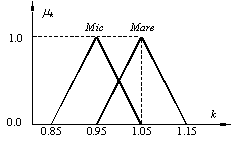
(a) (b)
Funcţiile de
apartenenţă pentru tensiune (a) şi raportul de transformare (b).


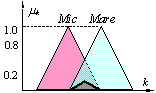
(a) (b) (c)
Rezultatul conectării
regulilor (13.23) prin maxim (a), minim (b) sau produs (c).
Pentru a
ilustra cele trei moduri de compunere a regulilor vom considera cazul unui
sistem fuzzy simplu format din două reguli:

pentru care funcţiile de
apartenenţă sunt cele de mai sus.
Defuzzificarea
Utilizarea
logicii fuzzy impune ca mărimile de intrare, care de regulă se
prezintă sub formă crisp, să suporte un proces de
fuzzificare. În etapa următoare are loc evaluarea regulilor ce
guvernează sistemul fuzzy modelat iar rezultatul acestor evaluări are
de asemenea caracter fuzzy (cu excepţia sistemelor de tip Takagi – Sugeno
– Kang), adică se prezintă sub forma unei mulţimi de valori ce
pot fi atribuite simultan mărimii de ieşire. În practică
însă sistemele tradiţionale folosesc valori exacte, de tip crisp.
Astfel, la finalul oricărui set de inferenţe fuzzy este necesară
aplicarea unui proces invers, de defuzzificare, care să
producă o mărime crisp pe baza mulţimii(lor) fuzzy ce
descrie(u) rezultatul.
Cea mai
răspândită metodă de defuzzificare este metoda centroidului;
alte metode utilizate uneori în studiul sistemelor fuzzy sunt metoda
înălţimii, metoda ariilor sau metoda ariei maxime.
Literatura de specialitate menţionează de asemenea şi alte
metode alternative.
Defuzzificarea prin
metoda centroidului
Metoda
centroidului, numită şi metoda centrului de greutate,
determină valoarea crisp asociată ieşirii unui sistem fuzzy prin
valoarea abscisei centrului de greutate al figurii geometrice care descrie
mulţimea fuzzy asociată ieşirii sistemului.
Pentru a ilustra modul de
aplicare a metodei centroidului, se consideră cazul generic al unui sistem
descris de trei reguli simple:
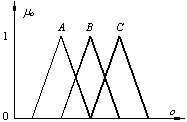
Sistemul conţine trei
mărimi de intrare (x, y şi z) definite pe mulţimile fuzzy X, Y şi
Z, respectiv o singură mărime de ieşire (o)
definită cu ajutorul a trei mulţimi fuzzy descrise de variabilele
lingvistice A, B şi C. Pentru mulţimile fuzzy A, B
şi C se consideră funcţii de apartenenţă
triunghiulare, distribuite pe universul de discurs conform reprezentării de
mai jos.
Se admite
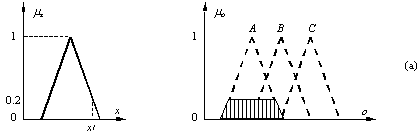
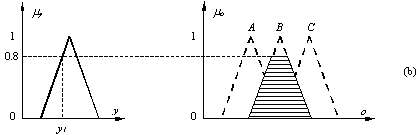
că, la un moment dat, pentru mărimile de intrare se stabilesc
valorile crisp x1 = 0.2, y1 = 0.8 şi z1
= 0.6, aşa cum se indică şi în Fig. a, b şi c. Pentru
aceste valori ale mărimilor de intrare, prin aplicarea regulilor din
relaţia (13.36) se stabilesc gradele de apartenenţă şi
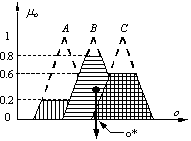
mulţimile fuzzy asociate. De asemenea, în Fig. d se prezintă
suprapunerea tăieturilor de nivel ale celor trei mulţimi fuzzy. În
raport cu reprezentarea din această figură, metoda centroidului
determină valoarea crisp asociată ieşirii fuzzy corespunzător
abscisei centrului de greutate al suprafeţei haşurate din figura (valoarea
crisp o*).

(d)